자율주행 관련 영상처리 프로젝트를 맡게 되면서, 자율주행시 오브젝트 인식 및 통과 가능여부, 회피여부를 판단하기 위한 모델을 공부하게 되었다. 회의에서는 일단 YOLO모델을 활용하여 Object Detection을 활용하고, 인식이 필요한 물체를 학습시키자는 의견이 나왔다.
하지만 조사결과 객체탐지 모델의 경우, 물체의 형상보다는 물체의 사각형의 위치정보만 반환하기 때문에, 자율주행에 적합하다고 생각했다.
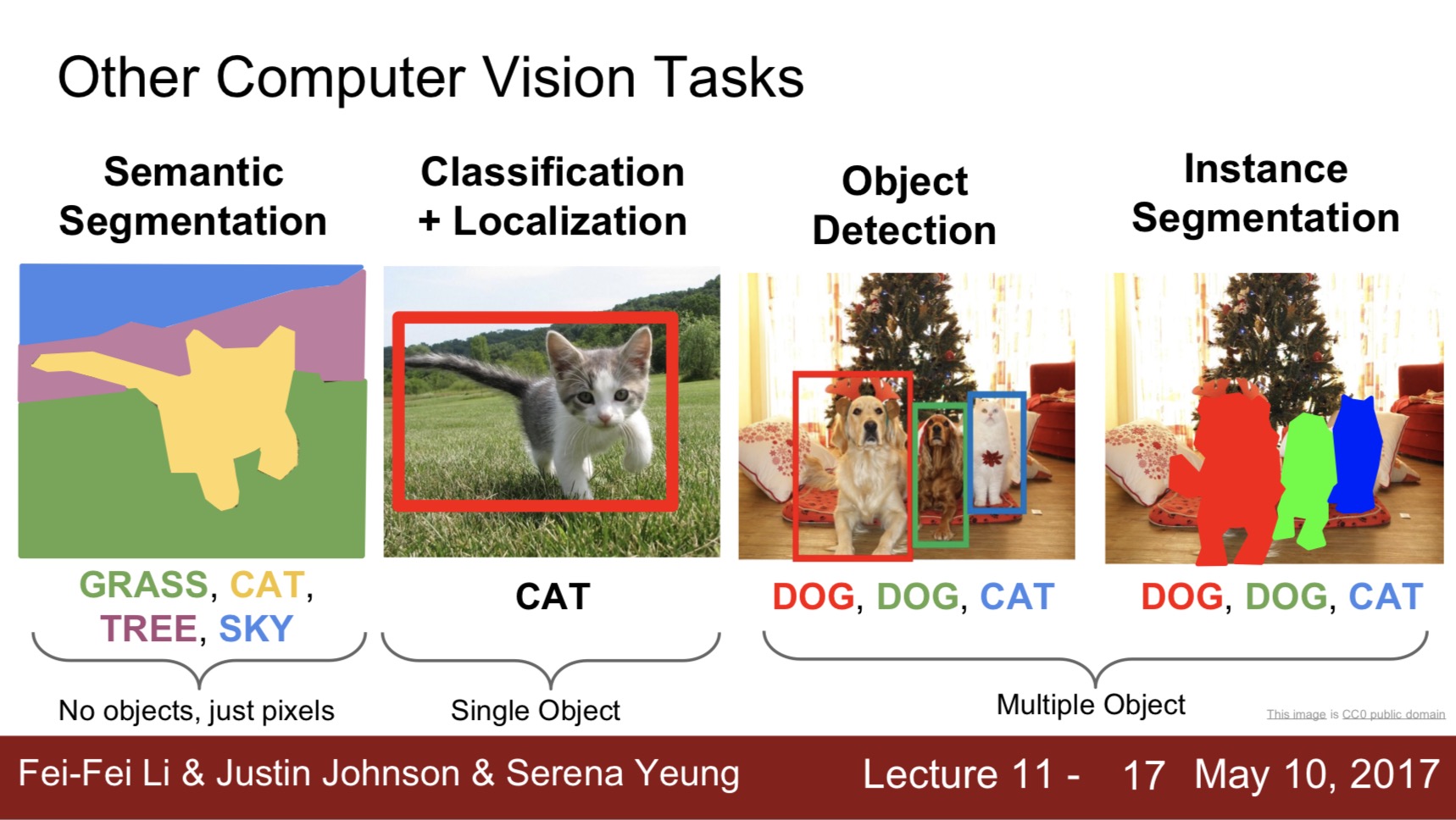
따라서, 조사결과 위의 사진처럼 Segmentation 모델을 찾게 되었는데, 물체의 분류 뿐만 아니라 물체의 형상까지 Mask처리해주는 모델이 있다는 것을 알게 되었다.
그런데 Segmetation 모델에도 여러 종류가 있었다. 크게 3가지로 분류를 하자면,
1. Semantic Segmentation 모델

Semantic Segmentation 모델은 사진의 모든 픽셀에 대해서 분류와 Masking 작업을 하는 모델을 말한다. 위의 사진처럼 사람은 모두 빨간색, 도로는 옅은 빨강, 인도는 핑크, 자동차는 파란색으로 나뉘는 것을 볼 수 있다. 사실 자율주행 관점에서 본다면, 도로를 인식하고, 도로위의 물체를 구별할 수 있다는 점에 있어서, 객체 탐지 모델모다는 유리할 것 같다.
대표적인 모델은 다음과 같다.
- FCN
- DeepLab v3
- U-Net
2. Instance Segmentation 모델

위의 사진을 보면 Semantic Segmentation과 Instatnce Segmentation을 확실하게 구분 할 수 있다. 즉, 사람에 대한 분류라도, 한 사람 한 사람이 다른 사람이라고 분류를 하는 것을 Instance Segmentation이라고 할 수 있다. 만약 자율주행 영상처리에서, 주변의 자동차를 tracking 한다고 했을 때, 자동차 각각에 대해서 추적을 해야 할 것이다. 그러한 상황에서는 Segmantic 보다는 Instance를 쓰는게 확실히 구분이 되어서, 추적이 용이 할 것이다. 하지만 단점으로는 보통 객체 탐지와 비슷하게 어떤 객체를 탐지하고 구분하기 때문에, 학습이 안된 정보에 대해서는 구분을 하지 않는것 같다.
대표적인 모델은 다음과 같다.
- Mask RCNN
- YOLACT
3. Panoptic Segmentation 모델
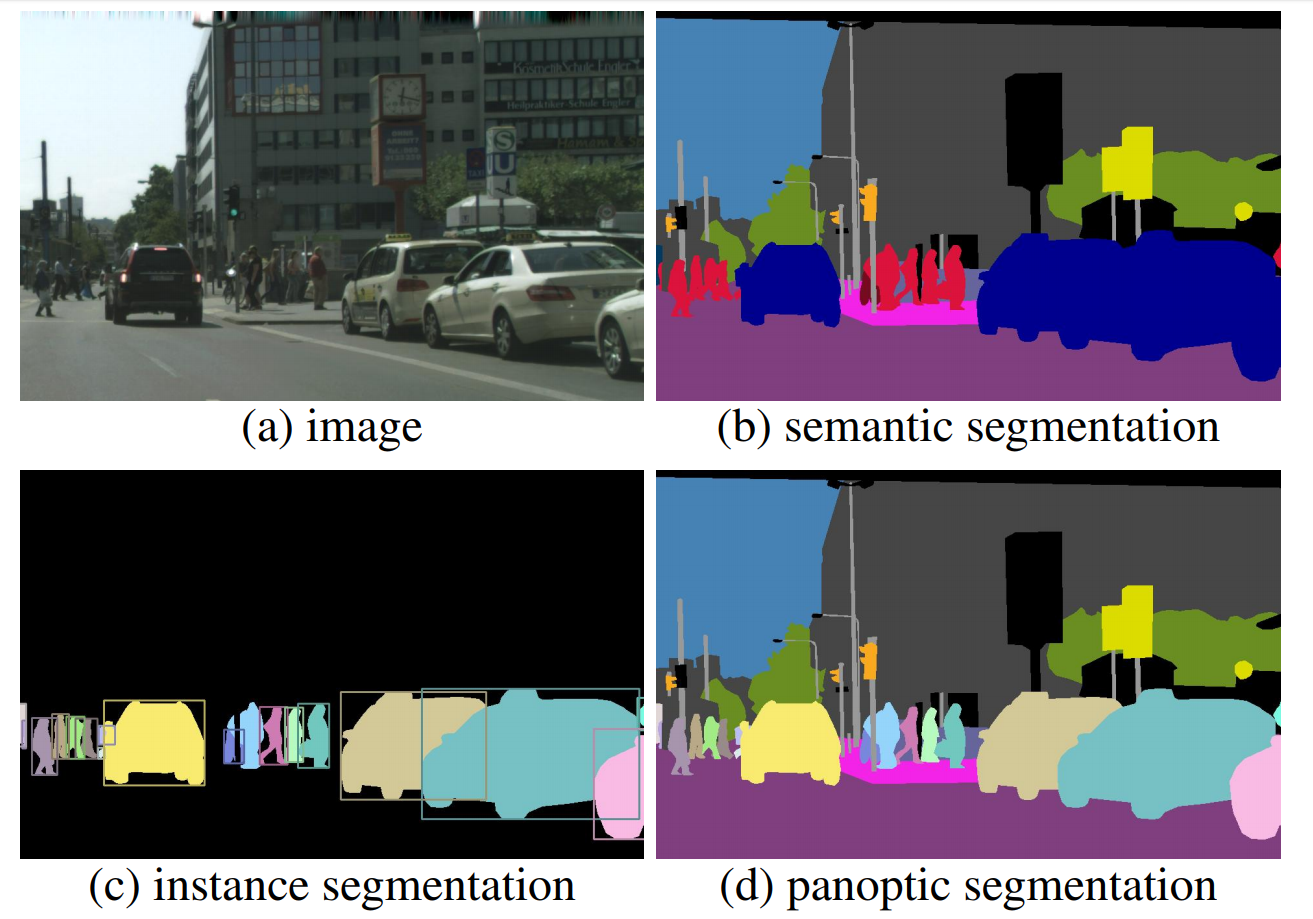
Panoptic Segmentation 모델은 위의 사진을 보면 이해하기 쉽다. 쉽게 말해서 semantic의 모든 픽셀에 대한 분류와, Instance의 각각의 개체에 대한 분류의 특징이 합쳐진 것으로 이해하면 된다. 생각하기에는 자율주행 영상처리와 판단에 있어서 가장 이상적인 모델인 것 같다.
알려진 모델로는 UPSNet이라는 모델이 있다.
조사 결과 일단 이미 학습되어 있고 사용이 편리하게 만들어진 모델은 Instance, Semantic 분야는 잘 알려져 있는 것 같다. 하지만 Panoptic의 UPSNet도 github에는 등록되어 있지만, 사용방법은 어려운 것 같아서, 좀 더 공부를 해야할 것 같다.
'Deep Learning > Segmentation' 카테고리의 다른 글
| DeepLabV3 사용법 - Semantic Segmentation (0) | 2021.01.26 |
|---|---|
| YOLACT 사용법 - Instance Segmentation (0) | 2021.01.25 |
| Mask R-CNN 사용법 - Instance Segmentation (0) | 2021.01.24 |